Persian ASR Leaderboard 🏆
The Persian Automatic Speech Recognition (ASR) Leaderboard ranks Hugging Face ASR models based on their performance on multiple Persian speech datasets. Models are evaluated using Word Error Rate (WER) and Character Error Rate (CER), with WER as the primary ranking metric (lower is better).
Check the 📈 Metrics tab for evaluation details. Want a model ranked? Submit a request via the "Request a Model" tab ✉️✨. This leaderboard helps compare Persian ASR models across different dialects and settings.
Persian ASR Model Rankings
Below is a list of models currently ranked on the Persian ASR Leaderboard. Each model has been evaluated across multiple Persian speech datasets to provide an accurate comparison based on their performance in recognizing Persian speech.
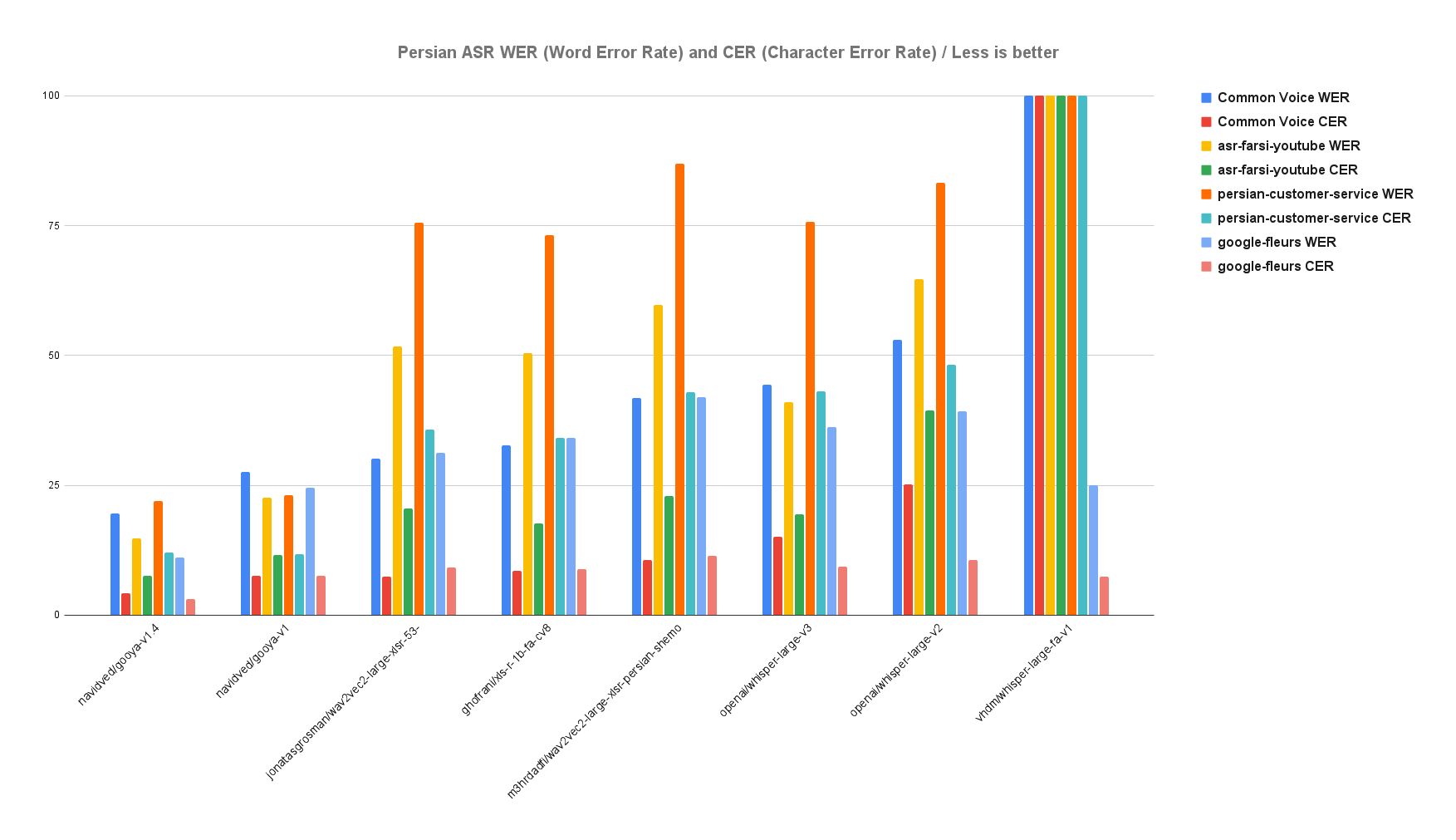
navidved/gooya-v1.4
An improved version of Gooya with a larger and cleaner dataset, leading to significant enhancements in accuracy. This version incorporates notable architectural improvements, resulting in lower Word Error Rate (WER) and Character Error Rate (CER) across multiple Persian ASR benchmarks.navidved/gooya-v1
A high-performing ASR model with particularly strong results on the Persian ASR Test Set. It shows a low WER and CER across various datasets, making it one of the top choices for Persian speech recognition.openai/whisper-large-v3
This model performs reasonably well on the ASR Farsi YouTube dataset, though it struggles more on the Persian ASR Test Set, indicating that it may be better suited for more casual or non-technical speech environments.ghofrani/xls-r-1b-fa-cv8
With balanced performance across all datasets, this model offers decent accuracy for both word and character recognition but faces challenges on more controlled datasets like the Persian ASR Test Set.jonatasgrosman/wav2vec2-large-xlsr-53-persian
A reliable ASR model that performs well on the Common Voice dataset but sees reduced accuracy in the more challenging Persian ASR Test Set and YouTube data. Suitable for more common conversational speech.m3hrdadfi/wav2vec2-large-xlsr-persian-shemo
This model is better suited for informal contexts, with higher WER and CER values across all datasets. It may struggle in more complex or structured speech recognition tasks.openai/whisper-large-v2
With the highest WER and CER across all datasets, this model underperforms in Persian speech recognition tasks, particularly on more difficult datasets like the Persian ASR Test Set.
Let me know if you want any modifications! 🚀
Model | Common Voice WER | Common Voice CER | asr-farsi-youtube WER | asr-farsi-youtube CER | persian-customer-service WER | persian-customer-service CER | google-fleurs WER | google-fleurs CER |
|---|---|---|---|---|---|---|---|---|
27.52 | 15.17 | 485.74 | 441.92 | 227.15 | 190.42 | 11.08 | 11.49 |
Evaluation Metrics and Datasets
Metrics
We employ the following metrics to evaluate the performance of Automatic Speech Recognition (ASR) models:
- Word Error Rate (WER): WER quantifies the proportion of incorrectly predicted words in a transcription. A lower WER reflects higher accuracy.
- Character Error Rate (CER): CER measures errors at the character level, providing a more granular view of transcription accuracy, especially in morphologically rich languages such as Persian. Both metrics are widely used in ASR evaluation, offering a comprehensive view of model performance.
Datasets
The models on the Persian ASR Leaderboard are evaluated using a diverse range of datasets to ensure robust performance across different speech conditions:
Persian Common Voice (Mozilla)
Available here, this dataset is part of the broader Common Voice project and features speech data from various speakers, accents, and environments. It serves as a representative benchmark for Persian ASR.ASR Farsi YouTube Chunked 10 Seconds
This dataset, available on Hugging Face here, consists of transcribed speech from Persian YouTube videos, split into 10-second segments. It introduces variability in audio quality and speaker demographics, adding to the challenge of accurate recognition.Persian-ASR-Test-Set (Private)
This private dataset is designed for in-depth model testing and evaluation. It contains curated, real-world Persian speech data from various contexts and speaker backgrounds. Access to this dataset is restricted, ensuring models are evaluated on a controlled, high-quality speech corpus.Google Fleurs Available here, this multilingual dataset includes Persian speech samples across various topics and dialects. It provides a standardized benchmark for evaluating ASR models across multiple languages, ensuring broad linguistic and acoustic coverage.
How to Submit Your Model for Evaluation
To request that a model be included on this leaderboard, please submit its name in the following format: username/model_name. Models should be available on the Hugging Face Hub for public access.
Simply navigate to the "Request a Model" tab, enter the details, and your model will be evaluated at the next available opportunity.
✉️✨ Request results for a new model here!
Last updated on Aug 22st 2025